
Now this is an interesting experiment that leads us very close to the touch point between machine classification and human imaginations.
As described in previous posts, auto-classification algorithms are using features that are extracted from the objects to be classified (images or text) and are represented in a feature space. Classification can be described as finding the correct separation plane (in many dimensions) between the features for different objects. A group of researchers from MIT (Carl Vondrick, Hamed Pirsiavash, Aude Oliva, Antonio Torralba) has now used an interesting approach to get a glimpse of how this feature space might actually exist and look like in our minds. They have generated random white noise in the feature space and inverted this noise to actual images. These images then have been presented to humans and they have been asked if they resembled certain well known objects. The results are quite fascinating:
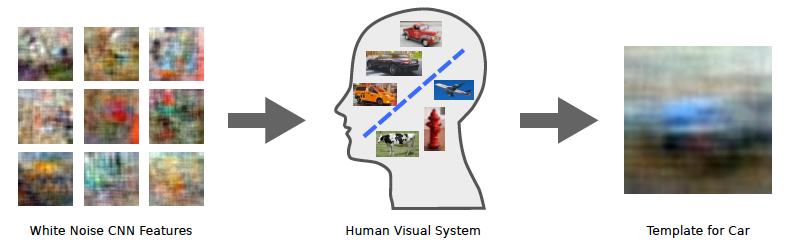
All image patches on the left are just noise. Many thousands of them were shown to online workers and they were asked them to find ones that look like cars. See full scientific paper here.
Most of the time these random images will appear to people as random. But every now and then somebody will feel that an image does remind them of a car. So we set this image aside. And repeat. After assessing 100,000 images in this way, we end up with a set of essentially random pictures that remind people of cars. We then take the average of these and find something interesting. The resulting image does indeed look like a blurry car, not a specific kind of car but a very general template of one.
Mathematically speaking this noise-driven method estimates the decision boundary that the human visual system uses for recognition.

My favorite example of the ones that have been tested is the fire hydrant that emerges from random white noise images.
Now as the random noise was actually generated in the feature space and not in the images themselves the researchers can deduct which features actually lead to the recognition of objects. And hence get an understanding on how human recognition of objects acually works. Because humans have some remarkable capabilities to recognize objects that they have never seen, touched or smelled before. This understanding of the actual feature selection in human minds will help us in the future to derive new classfiers that more closely resemble the way we all do object recognition and includes the human bias. Because this is one of the most interesting results of the study: The object that emerges depends on the cultural background of the persons selecting the random images. For example when online workers from India were asked to find a sports ball then a red circular object emerges. Because the most popular sport in India is cricket which is played with a red ball. Ask the same question to US workers then a orange ball appears – think of football or basketball.
The same question of human bias we find in our daily work in classification of documents in big enterprises. Every person will classify a document set a little different from their co-workers – thus leading to a lot of inconsistencies. Which can be overcome with auto-classification, which will always make predictable and consistent decisions.
The research described here provides a very interesting insight into the nature of human mind. It will also allow us to work on refined methods of classification that more closely resemble the way humans make decision.