
Wouldn’t it be nice if your AI enabled document processing system would continuously take the input from user interactions and use this information to improve the quality of recognition over time? And nobody would have to take care of this – even in the case of hundreds of document classes with dozens of index fields each. In the best case the system would be easy to set up, run completely unattended in background and work like a charm.
This is what Skilja with its Laera Classification and Extraction software suites provides. We have completely implemented this new paradigm which is available either as SDKs or as integrated modules to our Vinna Document Processing Platform. But of course what looks easy for the user requires significant infrastructure and automated checks and balances to make this a reliable and stable part of your processing tasks.
Machine Online-Learning of document classification and recognition uses supervised and unsupervised continuous training of incoming data streams. Supervised learning will take the corrections the users have made, analyze them and apply them as new patterns as appropriate. Unsupervised learning will use the results of successful and correct classification and extraction to generate additional knowledge (expanding the space) and statistics of usage of existing knowledge. Both combined are then used to continuously improve the system. The infrastructure is set up quickly and consists of services that do the work in the background: collect statistics, collect samples, analyze the validity of the new data and publish them to the production runtime system if the AI has determined them to be valid additions.
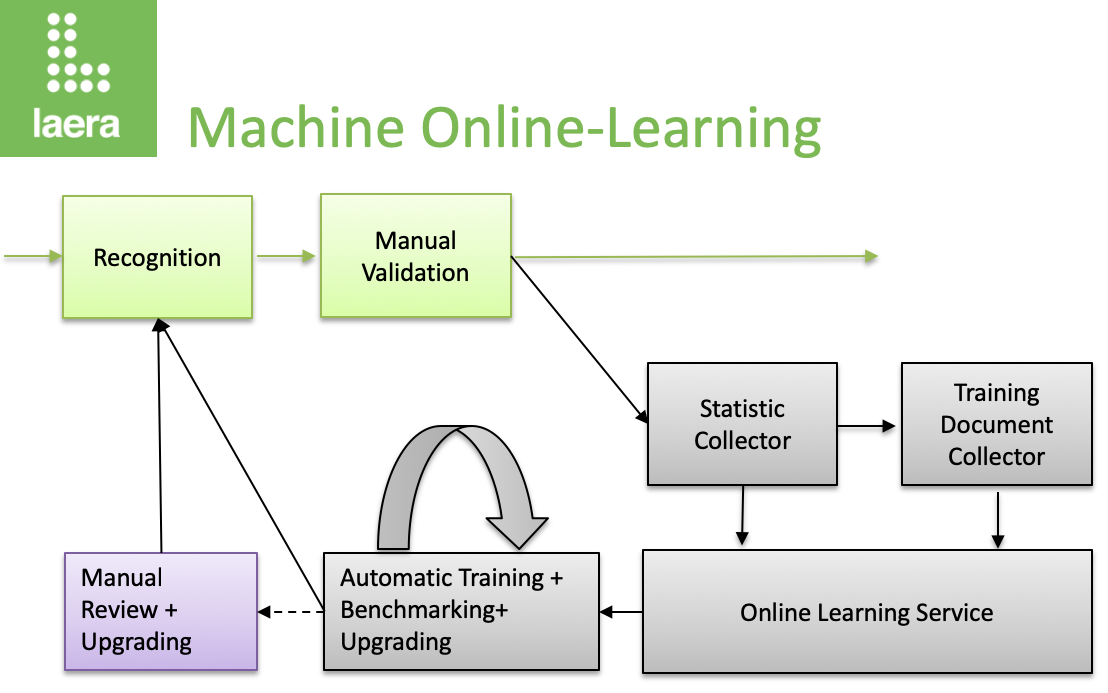
As we know that system administrators might be vary of having their setup changed automatically (at least until they have seen it really works) there is several intermediate levels of AI automation that they can chose. The most important are:
- Have all changes and each new document manually reviewed, benchmarked and checked before explicitly publishing it. This is the box on the left
- Have automatically created improvements be reviewed and explicitly published
- View any conflict and resolve them manually (or at least check them)
- Restrict the users that can contribute to the training to a certain group. Only corrections from this group will be taken into account while the input from less experienced users will be discarded.
But in the end learning can run completely unattended. As in school (think exams) we need to check the validity of the new knowledge before we apply it. Therefore Laera algorithms will always analyze for conflicts that are created and try to resolve them. Im addition each new revision of the training pattern will fully automatically be quality checked in background and only be accepted if the recognition results of the new model exceed the existing one. This is an assurance for the production system: Changes in quality will always only go into one direction – better!
Again, this is not a black box but Laera provides precise insight of what is happening and lets you influence or even revert the suggested improvements at any stage. Laera Monitor is the tool for this, a web application that shows the continuously measured quality numbers of your system.
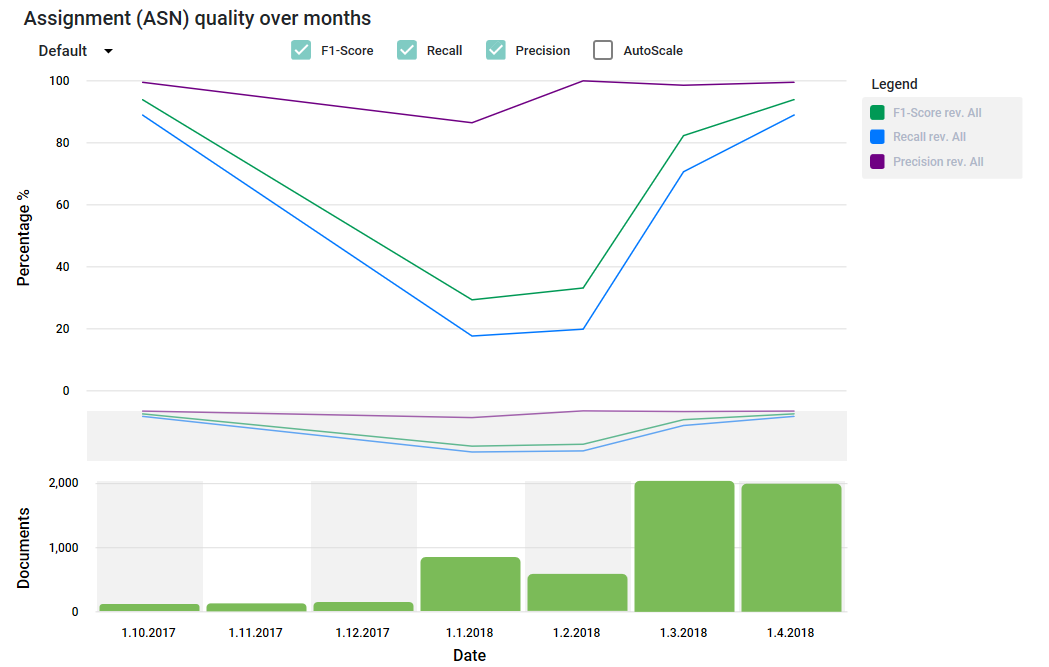
The example shown here shows a typical curve for the F1 score (average quality measurement). Starting with a setup of a few hundred trained documents the quality quickly deteriorates as new and unknown samples arrive in production. Especially when the real volumes start to be processed. It is interesting to see that the precision stays high close to 95% which is very satisfying, but recall (recognition rate) goes down as the system simply does not “know” the new documents. But then online learning kicks in and uses the new samples and corrections made to quickly improve the quality to 95% after a few thousand new training documents have been processed.
Online Learning will make classification and extraction much easier in the future. After an initial setup AI will simply learn in background what needs to be known to arrive at he best possible automation rate within a few weeks. This makes a whole new area of processes (for example with smaller document volumes) available and will greatly improve quality for existing automation processes.
Please let us know if you have additional questions or need more insight or have a direct interest. Contact us under info (at) skilja.com.